Introduction to Game Theory¶
A game refers to any interactive situation involving a group of “self-interested” agents, or players. The defining feature of a game is that the players are engaged in an “interdependent decision problem”.
Reading
M. Osborne, Nash Equilibrium: Theory, Chapter from Introduction to Game Theory, Oxford University Press, 2002.
D. Ross, Game Theory, Stanford Encyclopedia of Philosophy, 2019.
E. Pacuit and O. Roy, Epistemic Foundations of Game Theory, Stanford Encyclopedia of Philosophy, 2012.
# make graphs look nice
import seaborn as sns
sns.set()
The mathematical description of a game includes at least the following components:
The players. In this entry, we only consider games with finitely many players. We use \(N\) to denote the set of players in a game.
For each player \(i\in N\), a finite set of feasible options (typically called actions or strategies).
For each player \(i\in N\), a preference over the possible outcomes of the game. The standard approach in game theory is to represent each player’s preference as a (von Neumann-Morgenstern) utility function that assigns a real number to each outcome of the game.
A game may represent other features of the strategic situation. For instance, some games represent multi-stage decision problems which may include simultaneous or stochastic moves. For simplicity, we start with games that involve players making a single decision simultaneously without stochastic moves.
A game in strategic form is a tuple \(\langle N, (S_i)_{i\in N}, (u_i)_{i\in N}\rangle\) where:
\(N\) is a finite non-empty set
For each \(i\in N\), \(S_i\) is a finite non-empty set
For each \(i\in N\), \(u_i:\times_iS_i \rightarrow\mathbb{R}\) is player \(i\)’s utility.
The elements of \(\times_{i\in N} S_i\) are the outcomes of the game and are called strategy profiles.
In most games, no single player has total control over which outcome will be realized at the end of the interaction. The outcome of a game depends on the decisions of all players.
The central analytic tool of classical game theory are solution concepts. A solution concept associates a set of outcomes (i.e., a set of strategy profiles) with each game (from some fixed class of games).
From a prescriptive point of view, a solution concept is a recommendation about what the players should do in a game, or about what outcomes can be expected assuming that the players choose rationally. From a predictive point of view, solution concepts describe what the players will actually do in a game.
Nash Equilibrium¶
Let \(G=\langle N, (S_i)_{i\in N}, (u_i)_{i\in N}\rangle\) be a finite strategic game (each \(S_i\) is finite and the set of players \(N\) is finite).
A strategy profile is an element \(\times_{i\in N} S_i\)
Given a strategy profile \(\sigma\in \times_{i\in N}S_i\), \(\sigma_{-i}\) is an element of $\( S_1\times S_2\times\cdots S_{i-1}\times S_{i+1}\times \cdots S_n\)$
A strategy profiel \(\sigma\) is a pure strategy Nash equilibrium provided that for all \(i\in N\), for all \(a\in S_i\), $\(u_i(\sigma) \ge u_i(a, \sigma_{-i})\)$
Pure Coordination Game¶
|
\(S1\) |
\(S2\) |
|---|---|---|
\(S1\) |
\((1, 1)\) |
\((0, 0)\) |
\(S2\) |
\((0, 0)\) |
\((1, 1)\) |
There are two pure strategy Nash equilibria: \((S1, S1)\) and \((S2, S2)\)
The basic intellectual premise, or working hypothesis, for rational players in this game seems to be the premise that some rule must be used if success is to exceed coincidence, and that the best rule to be found, whatever its rationalization, is consequently a rational rule. (T. Schelling, The Strategy of Conflict, pg. 283)
Hi-Lo Game¶
|
\(S1\) |
\(S2\) |
|---|---|---|
\(S1\) |
\((3, 3)\) |
\((0, 0)\) |
\(S2\) |
\((0, 0)\) |
\((1, 1)\) |
There are two pure strategy Nash equilibria: \((S1, S1)\) and \((S2, S2)\)
There are these two broad empirical facts about Hi-Lo games, people almost always choose [\(S1\)] and people with common knowledge of each other’s rationality think it is obviously rational to choose [\(S1\)].” (M. Bacharach, Beyond Individual Choice, p. 42)
Matching Pennies¶
|
\(S1\) |
\(S2\) |
|---|---|---|
\(S1\) |
\((1, -1)\) |
\((-1, 1)\) |
\(S2\) |
\((-1, 1)\) |
\((1, -1)\) |
There are no pure strategy Nash equilibria.
A mixed strategy for player \(i\) in a finite game \(\langle N, (S_i)_{i\in N}, (u_i)_{i\in N}\rangle\) is a lottery on \(S_i\), i.e., a probability over player \(i\)’s strategies.
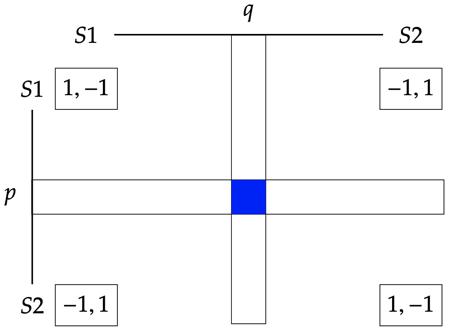
The utilities for a mixed strategy profile \((p, q)\) is:
We are reluctant to believe that our decisions are made at random. We prefer to be able to point to a reason for each action we take. Outside of Las Vegas we do not spin roulettes. (A. Rubinstein, Comments on the Interpretation of Game Theory, Econometrica 59, 909 - 924, 1991)
What does it mean to play a mixed strategy?
Randomize to confuse your opponent (e.g., matching pennies games)
Players randomize when they are uncertain about the other’s action (e.g., battle of the sexes game)
Mixed strategies are a concise description of what might happen in repeated play
Mixed strategies describe population dynamics: After selecting 2 agents from a population, a mixed strategy is the probability of getting an agent who will play one pure strategy or another.
|
\(S1\) |
\(S2\) |
|---|---|---|
\(S1\) |
\((1, -1)\) |
\((-1, 1)\) |
\(S2\) |
\((-1, 1)\) |
\((1, -1)\) |
There is one mixed strategy Nash equilibria: \(((1/2: S1, 1/2: S2), (1/2:S1, 1/2:S2))\).
Battle of the Sexes¶
|
\(S1\) |
\(S2\) |
|---|---|---|
\(S1\) |
\((2, 1)\) |
\((0, 0)\) |
\(S2\) |
\((0, 0)\) |
\((1, 2)\) |
There are two pure strategy Nash equilibrium \((S1, S1)\) and \((S2, S2)\) (and one mixed strategy Nash equilibrium).
Stag Hunt¶
|
\(S1\) |
\(S2\) |
|---|---|---|
\(S1\) |
\((3, 3)\) |
\((0, 2)\) |
\(S2\) |
\((2, 0)\) |
\((1, 1)\) |
There are two pure strategy Nash equilibrium \((S1, S1)\) and \((S2, S2)\). While \((S1, S1)\) Pareto dominates \((S1, S1)\), but \((S2, S2)\) is ‘less risky’.
The problem of instituting, or improving, the social contract can be thought of as the problem of moving from riskless hunt hare equilibrium to the risky but rewarding stag hunt equilibrium. (B. Skyrms, Stag Hunt and the Evolution of Social Structure, p. 9)
Prisoner’s Dilemma¶
|
\(S1\) |
\(S2\) |
|---|---|---|
\(S1\) |
\((3, 3)\) |
\((0, 4)\) |
\(S2\) |
\((4, 0)\) |
\((1, 1)\) |
There is one Nash equilibrium \((S2, S2)\). The non-equilibrium \((S1, S1)\) Pareto-dominates \((S2, S2)\).
Game theorists think it just plain wrong to claim that the Prisoners’ Dilemma embodies the essence of the problem of human cooperation. On the contrary, it represents a situation in which the dice are as loaded against the emergence of cooperation as they could possibly be. If the great game of life played by the human species were the Prisoner’s Dilemma, we wouldn’t have evolved as social animals!….No paradox of rationality exists. Rational players don’t cooperate in the Prisoners’ Dilemma, because the conditions necessary for rational cooperation are absent in this game. (K. Binmore, Natural Justice, p. 63)
Game Theory in Python¶
Gambit - https://gambitproject.readthedocs.io/en/latest/index.html: a library of game theory software and tools for the construction and analysis of finite extensive and strategic games.
Nashpy - https://nashpy.readthedocs.io/en/latest/: a simple library used for the computation of equilibria in 2 player strategic form games.
Axelrod - https://axelrod.readthedocs.io/en/stable/index.html: a library to study iterated prisoner’s dilemma.
Nashpy¶
import nashpy as nash
import numpy as np
# Coordination Game
A = np.array([[1, 0], [0, 1]])
B = np.array([[1, 0], [0, 1]])
coord = nash.Game(A, B)
print(coord)
print([1,2])
print(np.array([1,2]))
Bi matrix game with payoff matrices:
Row player:
[[1 0]
[0 1]]
Column player:
[[1 0]
[0 1]]
[1, 2]
[1 2]
sigma1_r = [1, 0]
sigma1_c = [0, 1]
print("The utilities are ", coord[sigma1_r, sigma1_c])
sigma2_r = [1 / 2, 1 / 2]
sigma2_c = [1 / 2, 1 / 2]
print("The utilities are ", coord[sigma2_r, sigma2_c])
eqs = coord.support_enumeration()
print("The Nash equilibria are:")
for ne in eqs:
print("\t", ne)
The utilities are [0 0]
The utilities are [0.5 0.5]
The Nash equilibria are:
(array([1., 0.]), array([1., 0.]))
(array([0., 1.]), array([0., 1.]))
(array([0.5, 0.5]), array([0.5, 0.5]))
# Hi-Lo
A = np.array([[3, 0], [0, 1]])
B = np.array([[3, 0], [0, 1]])
hilo = nash.Game(A, B)
eqs = hilo.support_enumeration()
print("The Nash equilibria for Hi-Lo are:")
for ne in eqs:
print("\t", ne)
The Nash equilibria for Hi-Lo are:
(array([1., 0.]), array([1., 0.]))
(array([0., 1.]), array([0., 1.]))
(array([0.25, 0.75]), array([0.25, 0.75]))
# Battle of the Sexes
A = np.array([[2, 0], [0, 1]])
B = np.array([[1, 0], [0, 2]])
bos = nash.Game(A, B)
eqs = bos.support_enumeration()
print("The Nash equilibria for Battle of the Sexes are:")
for ne in eqs:
print("\t", ne)
The Nash equilibria for Battle of the Sexes are:
(array([1., 0.]), array([1., 0.]))
(array([0., 1.]), array([0., 1.]))
(array([0.66666667, 0.33333333]), array([0.33333333, 0.66666667]))
# Stag Hunt
A = np.array([[3, 0], [2, 1]])
B = np.array([[3, 2], [0, 1]])
sh = nash.Game(A, B)
eqs = sh.support_enumeration()
print("The Nash equilibria for the Stag Hunt are:")
for ne in eqs:
print("\t", ne)
The Nash equilibria for the Stag Hunt are:
(array([1., 0.]), array([1., 0.]))
(array([0., 1.]), array([0., 1.]))
(array([0.5, 0.5]), array([0.5, 0.5]))
# Prisoner's Dilemma
A = np.array([[3, 0], [4, 1]])
B = np.array([[3, 4], [0, 1]])
pd = nash.Game(A, B)
eqs = pd.support_enumeration()
print("The Nash equilibria for the Prisoner's Dilemma are:")
for ne in eqs:
print("\t", ne)
The Nash equilibria for the Prisoner's Dilemma are:
(array([0., 1.]), array([0., 1.]))
Axelrod¶
Axelrod is a Python package to study repeated play of the Prisoner’s Dilemma:
|
\(S1\) |
\(S2\) |
|---|---|---|
\(S1\) |
\((3, 3)\) |
\((0, 4)\) |
\(S2\) |
\((4, 0)\) |
\((1, 1)\) |
There are different ways to repeat play of PD:
Two players repeatedly playing a PD
Multiple players repeatedly playing PD against each other
Multiple players repeatedly playing PD against their neighbors
Running a Match¶
In a Match, two player repeatedly play a PD.
import axelrod as axl
players = (axl.Cooperator(), axl.Alternator())
match = axl.Match(players, 5)
print("Match Play: ", match.play())
print("Match Scores: ", match.scores())
print("Final Scores: ", match.final_score())
print("Final Scores Per Turn: ", match.final_score_per_turn())
print("Winner: ", match.winner())
print("Cooperation: ", match.cooperation())
print("Normalized Coperation: ", match.normalised_cooperation())
Match Play: [(C, C), (C, D), (C, C), (C, D), (C, C)]
Match Scores: [(3, 3), (0, 5), (3, 3), (0, 5), (3, 3)]
Final Scores: (9, 19)
Final Scores Per Turn: (1.8, 3.8)
Winner: Alternator
Cooperation: (5, 3)
Normalized Coperation: (1.0, 0.6)
players = (axl.Cooperator(), axl.Random())
match = axl.Match(players=players, turns=10, noise=0.0)
match.play()
print("Match Scores: ", match.scores())
print("Final Scores: ", match.final_score())
print("Final Scores Per Turn: ", match.final_score_per_turn())
print("Winner: ", match.winner())
print("Cooperation: ", match.cooperation())
print("Normalized Coperation: ", match.normalised_cooperation())
Match Scores: [(3, 3), (0, 5), (0, 5), (3, 3), (3, 3), (3, 3), (0, 5), (3, 3), (3, 3), (3, 3)]
Final Scores: (21, 36)
Final Scores Per Turn: (2.1, 3.6)
Winner: Random: 0.5
Cooperation: (10, 7)
Normalized Coperation: (1.0, 0.7)
Running a Tournament¶
In a tournament, each player plays every other player.
import pprint
players = [axl.Cooperator(), axl.Defector(),
axl.TitForTat(), axl.Grudger()]
tournament = axl.Tournament(players)
results = tournament.play(progress_bar=False)
print("Ranked players: ", results.ranked_names)
print("Normalized Scores: ", results.normalised_scores )
print("Wins: ", results.wins)
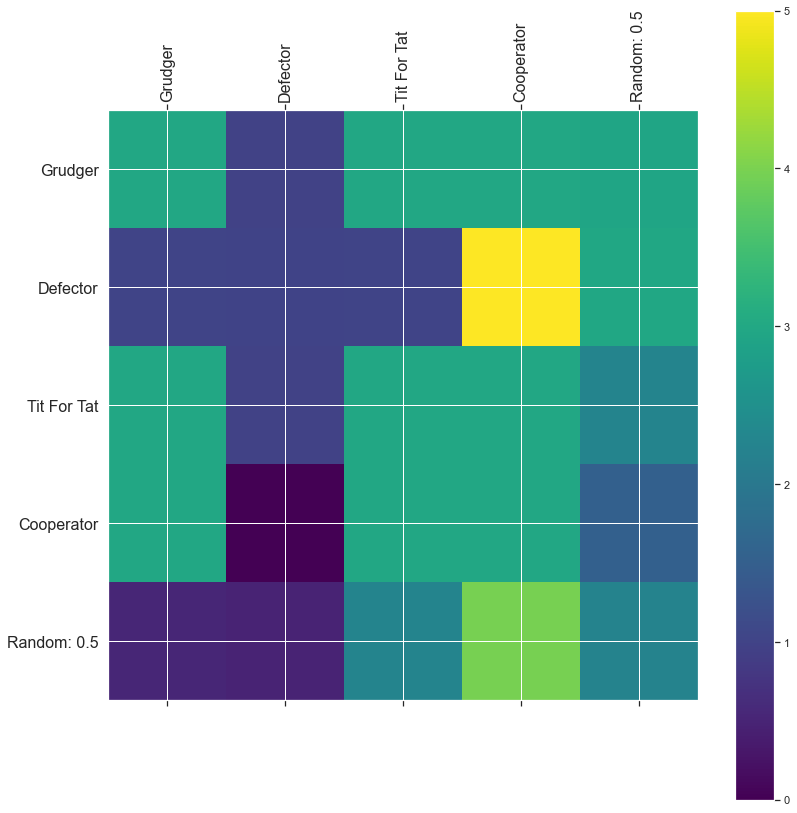
print("payoff matrix")
pprint.pprint(results.payoff_matrix);
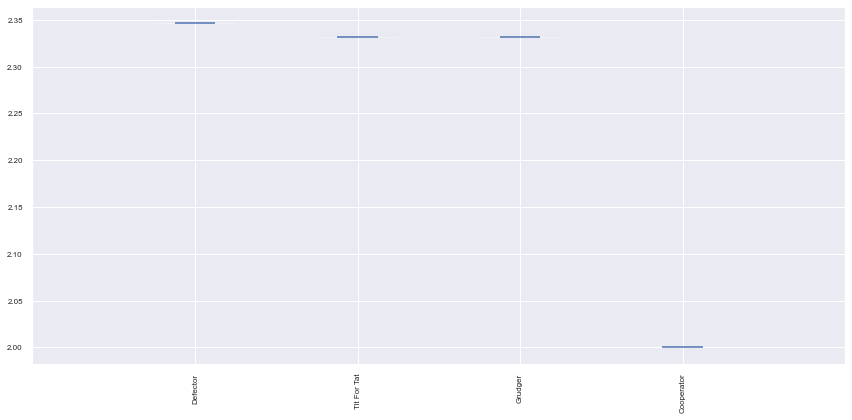
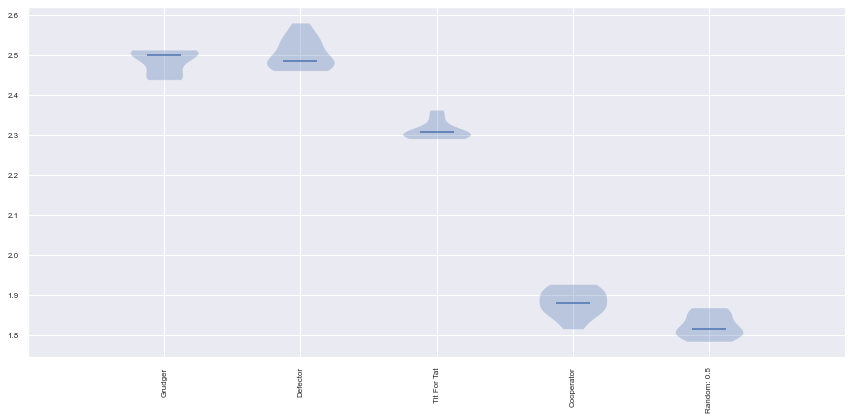
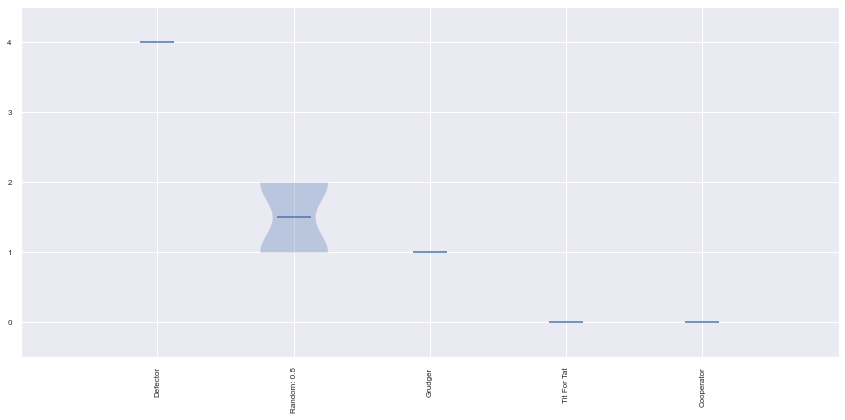
Ranked players: ['Defector', 'Tit For Tat', 'Grudger', 'Cooperator']
Normalized Scores: [[2.0, 2.0, 2.0, 2.0, 2.0, 2.0, 2.0, 2.0, 2.0, 2.0], [2.3466666666666662, 2.3466666666666662, 2.3466666666666662, 2.3466666666666662, 2.3466666666666662, 2.3466666666666662, 2.3466666666666662, 2.3466666666666662, 2.3466666666666662, 2.3466666666666662], [2.3316666666666666, 2.3316666666666666, 2.3316666666666666, 2.3316666666666666, 2.3316666666666666, 2.3316666666666666, 2.3316666666666666, 2.3316666666666666, 2.3316666666666666, 2.3316666666666666], [2.3316666666666666, 2.3316666666666666, 2.3316666666666666, 2.3316666666666666, 2.3316666666666666, 2.3316666666666666, 2.3316666666666666, 2.3316666666666666, 2.3316666666666666, 2.3316666666666666]]
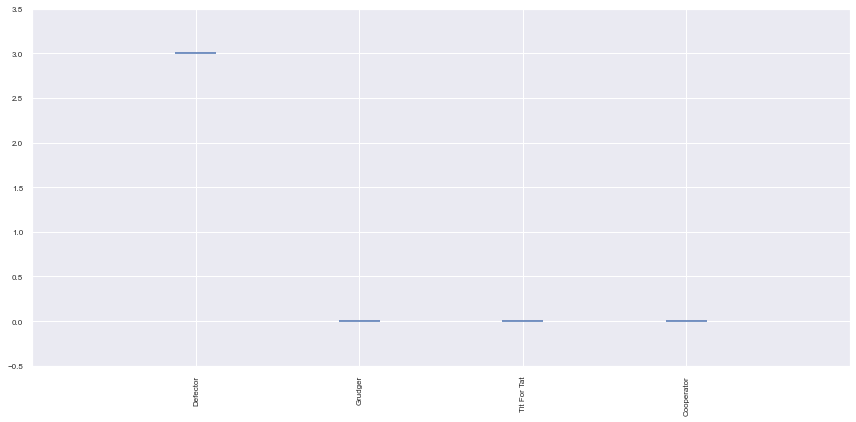
Wins: [[0, 0, 0, 0, 0, 0, 0, 0, 0, 0], [3, 3, 3, 3, 3, 3, 3, 3, 3, 3], [0, 0, 0, 0, 0, 0, 0, 0, 0, 0], [0, 0, 0, 0, 0, 0, 0, 0, 0, 0]]
payoff matrix
[[3.0, 0.0, 3.0, 3.0],
[5.0, 1.0, 1.02, 1.02],
[3.0, 0.9949999999999999, 3.0, 3.0],
[3.0, 0.9949999999999999, 3.0, 3.0]]
plot = axl.Plot(results)
plot.boxplot();
plot.winplot();
players = [axl.Cooperator(), axl.Defector(),
axl.TitForTat(), axl.Grudger(), axl.Random()]
tournament = axl.Tournament(players)
results = tournament.play(progress_bar=False)
print(results.ranked_names)
plot = axl.Plot(results)
plot.boxplot();
['Grudger', 'Defector', 'Tit For Tat', 'Cooperator', 'Random: 0.5']
p = plot.winplot()
plot.payoff();
Axelrod’s Tournament¶
In 1980, Robert Axelrod (a political scientist) invited submissions to a computer tournament version of an iterated prisoners dilemma (“Effective Choice in the Prisoner’s Dilemma”).
15 strategies submitted.
Round robin tournament with 200 stages including a 16th player who played randomly.
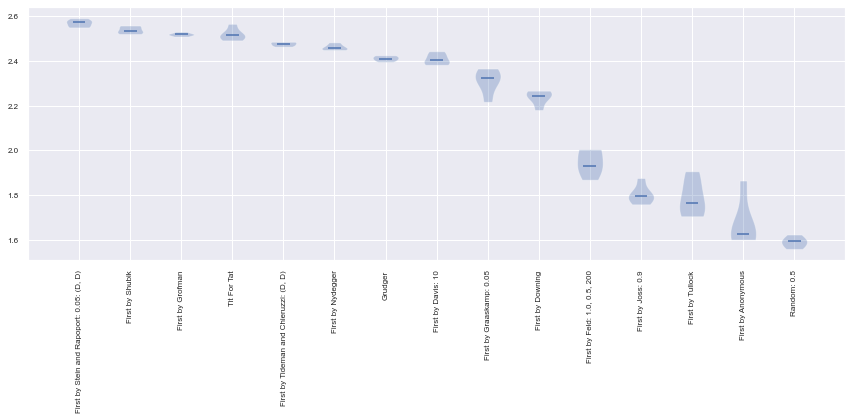
The winner (average score) was in fact a very simple strategy: Tit For Tat. This strategy starts by cooperating and then repeats the opponents previous move.
The fact that Tit For Tat won garnered a lot of (still ongoing) research. For an overview o of how to use axelrod to reproduce this first tournament, see http://axelrod.readthedocs.io/en/stable/reference/overview_of_strategies.html#axelrod-s-first-tournament.
axelrod_first_tournament = [s() for s in axl.axelrod_first_strategies]
number_of_strategies = len(axelrod_first_tournament)
for player in axelrod_first_tournament:
print(player)
Tit For Tat
First by Tideman and Chieruzzi: (D, D)
First by Nydegger
First by Grofman
First by Shubik
First by Stein and Rapoport: 0.05: (D, D)
Grudger
First by Davis: 10
First by Graaskamp: 0.05
First by Downing
First by Feld: 1.0, 0.5, 200
First by Joss: 0.9
First by Tullock
First by Anonymous
Random: 0.5
tournament = axl.Tournament(
players=axelrod_first_tournament,
turns=200,
repetitions=5,
)
results = tournament.play(progress_bar=False)
for name in results.ranked_names:
print(name)
First by Stein and Rapoport: 0.05: (D, D)
First by Shubik
First by Grofman
Tit For Tat
First by Tideman and Chieruzzi: (D, D)
First by Nydegger
Grudger
First by Davis: 10
First by Graaskamp: 0.05
First by Downing
First by Feld: 1.0, 0.5, 200
First by Joss: 0.9
First by Tullock
First by Anonymous
Random: 0.5
plot = axl.Plot(results)
plot.boxplot();
There are over 200 strategies implemented in axelrod (see https://axelrod.readthedocs.io/en/stable/reference/all_strategies.html). Including some recent strategies that have done quite well in tournaments:
Press, William H. and Freeman J. Dyson (2012), Iterated prisoner’s dilemma contains strategies that dominate any evolutionary opponent. Proceedings of the National Academy of Sciences, 109, 10409–10413.
players = [ axl.ZDExtort2(), axl.ZDSet2(), axl.TitForTat()]
tournament = axl.Tournament(
players=players,
turns=200,
repetitions=5,
)
results = tournament.play(progress_bar=False)
for name in results.ranked_names:
print(name)
ZD-SET-2: 0.25, 0.0, 2
Tit For Tat
ZD-Extort-2: 0.1111111111111111, 0.5
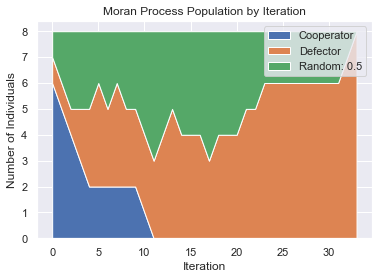
Moran Process¶
Given an initial population of players, the population is iterated in rounds consisting of:
matches played between each pair of players, with the cumulative total scores recorded.
a player is chosen to reproduce proportional to the player’s score in the round.
a player is chosen at random to be replaced.
players = [axl.Cooperator(),
axl.Cooperator(),axl.Cooperator(),axl.Cooperator(), axl.Cooperator(),
axl.Cooperator(),
axl.Defector(), axl.Random()]
mp = axl.MoranProcess(players, turns=100)
mp.play()
print("Winning strategy: ", mp.winning_strategy_name)
mp.populations_plot();
Winning strategy: Defector
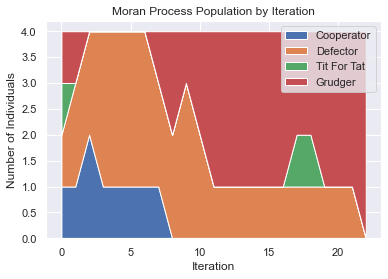
Moran Process with Mutation¶
players = [axl.Cooperator(), axl.Defector(),
axl.TitForTat(), axl.Grudger()]
mp = axl.MoranProcess(players, turns=100, mutation_rate=0.1)
for _ in mp:
if len(mp.population_distribution()) == 1:
break
mp.populations_plot();